与爱车同行的,除了风景,还有平安好车主!!!
开车上路,谁都怕遭遇刮擦、碰撞这类糟心事,理赔流程繁琐、修车垫付花钱,分分钟让人头大!别慌,中国平安好车主 APP 车险...
2025-11-09
从数学基础到边缘实现,研究团队: Conecta.ai (ufrn.br)

摘要
1.引言
2.GEMMA 2:通用集成机器模型算法
2.1 模型架构
2.2 预训练
2.3 后训练
3.边缘AI实现
1. 引言
GEMMA 2(通用集成机器模型算法,第二版)是一个复杂的框架,专为可扩展和灵活的机器学习模型训练而设计,特别是在分布式和资源受限的环境中。在其前身的基础上,GEMMA 2引入了增强的功能,适用于监督和无监督学习任务,使其成为人工智能、边缘计算和数据科学等领域研究人员和从业者的强大工具。
GEMMA 2的核心在于其能够处理多样化的数据集和模型架构,同时优化计算效率。这是通过算法设计中的创新实现的,包括支持自适应聚类、多分辨率数据分析和量化技术,确保与微控制器和嵌入式系统等资源受限设备的兼容性。
GEMMA 2的主要特点包括:
1.分布式学习:利用并行计算在多个节点上实现更快的训练和评估。
2.模型压缩:采用先进的量化和剪枝策略,在不牺牲准确性的情况下减小模型大小。
3.边缘部署:针对在边缘设备上部署机器学习模型进行定制优化,确保实时性能和最小能耗。
4.增强的灵活性:支持广泛的机器学习范式,包括神经网络、决策树和集成方法。
5.以用户为中心的设计:模块化架构和用户友好的API,简化了特定用例的集成和定制。
2 — Gemma 2
Gemma 2模型基于仅解码器的Transformer架构。我们在表中总结了主要参数和架构选择。
一些架构元素与Gemma模型的第一版相似;即上下文长度为8192个标记,使用旋转位置嵌入(RoPE)和近似的GeGLU非线性。Gemma 1和Gemma 2之间有几个元素不同,包括使用更深的网络。我们在下面总结了关键差异。
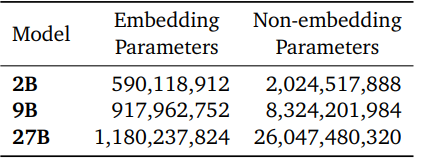
2.1 模型架构
2.1.1 局部滑动窗口和全局注意力
我们在每一层交替使用局部滑动窗口注意力和全局注意力。局部注意力层的滑动窗口大小设置为4096个标记,而全局注意力层的跨度设置为8192个标记。
2.1.2 Logit软限制
我们在每个注意力层和最终层对logit进行限制,使其值保持在−soft_cap和+soft_cap之间。更具体地说,我们使用以下函数对logit进行限制:
我们将self-attention层的soft_cap参数设置为50.0,将最终层的soft_cap参数设置为30.0。
2.1.3 使用RMSNorm的后归一化和前归一化
为了稳定训练,我们使用RMSNorm对每个Transformer子层、注意力层和前馈层的输入和输出进行归一化。
2.1.4 分组查询注意力
这种技术帮助模型更高效地处理信息,特别是在处理大量文本时。它通过将查询分组在一起,改进了传统的多头注意力(MHA),实现了更快的处理,特别是对于大型模型。这就像将一个大任务分成更小、更易管理的部分,使模型能够更快地理解单词之间的关系,而不牺牲准确性。
Gemma2ForCausalLM( (model):Gemma2Model( (embed_tokens):Embedding(256000,4608, padding_idx=0) (layers):ModuleList( (0-45):46xGemma2DecoderLayer( (self_attn):Gemma2SdpaAttention( (q_proj):Linear(in_features=4608, out_features=4096, bias=False) (k_proj):Linear(in_features=4608, out_features=2048, bias=False) (v_proj):Linear(in_features=4608, out_features=2048, bias=False) (o_proj):Linear(in_features=4096, out_features=4608, bias=False) (rotary_emb):Gemma2RotaryEmbedding() ) (mlp):Gemma2MLP( (gate_proj):Linear(in_features=4608, out_features=36864, bias=False) (up_proj):Linear(in_features=4608, out_features=36864, bias=False) (down_proj):Linear(in_features=36864, out_features=4608, bias=False) (act_fn):PytorchGELUTanh() ) (input_layernorm):Gemma2RMSNorm() (post_attention_layernorm):Gemma2RMSNorm() (pre_feedforward_layernorm):Gemma2RMSNorm() (post_feedforward_layernorm):Gemma2RMSNorm() ) ) (norm):Gemma2RMSNorm() ) (lm_head):Linear(in_features=4608, out_features=256000, bias=False))
2.2 预训练
简要概述我们与Gemma 1不同的预训练部分。
2.2.1 训练数据
Gemma 2 27B模型在13万亿个主要是英语数据的标记上进行训练,9B模型在8万亿个标记上进行训练,2B模型在2万亿个标记上进行训练。这些标记来自多种数据源,包括网页文档、代码和科学文章。我们的模型不是多模态的,也不是专门为最先进的多语言能力而训练的。最终的数据混合是通过类似于Gemini 1.0中的方法确定的。
分词器:使用与Gemma 1和Gemini相同的分词器:一个带有数字分割、保留空白和字节级编码的SentencePiece分词器。生成的词汇表有256k个条目。
过滤:使用与Gemma 1相同的数据过滤技术。具体来说,我们过滤预训练数据集以减少不需要或不安全的话语的风险,过滤掉某些个人信息或其他敏感数据,从预训练数据混合中净化评估集,并通过最小化敏感输出的扩散来减少重复的风险。
2.2.2 知识蒸馏
给定一个用作教师的大型模型,我们通过从教师给出的每个标记x在其上下文xc下的概率PT(x | xc)中进行蒸馏来学习较小的模型。更准确地说,我们最小化教师和学生概率之间的负对数似然:

其中PS是学生的参数化概率。注意,知识蒸馏也在Gemini 1.5中使用过。
2.3 后训练
对于后训练,我们将预训练模型微调为指令调优模型。首先,我们在纯文本、仅英语的合成和人工生成的提示-响应对混合上进行监督微调(SFT)。然后,我们在这些模型上应用RLHF,奖励模型是在仅英语的标记偏好数据上训练的,策略基于与SFT阶段相同的提示。最后,我们对每个阶段后获得的模型进行平均,以提高它们的整体性能。最终的数据混合和后训练配方,包括调整的超参数,是根据在提高有用性的同时最小化与安全和幻觉相关的模型危害而选择的。
我们扩展了Gemma 1.1的后训练数据,使用了内部和外部公共数据的混合。特别是,我们使用了LMSYS-chat-1M中的提示,但没有使用答案。我们所有的数据都经过下面描述的过滤阶段。
监督微调(SFT):我们在合成和真实的提示以及主要由教师(一个更大的模型)合成的响应上运行行为克隆。我们还在学生的分布上从教师那里进行蒸馏。
基于人类反馈的强化学习(RLHF):我们使用与Gemma 1.1类似的RLHF算法,但使用了不同的奖励模型,该模型比策略大一个数量级。新的奖励模型也更侧重于对话能力,特别是多轮对话。
模型合并:我们对通过使用不同超参数运行我们的流程获得的不同模型进行平均。
数据过滤:当使用合成数据时,我们运行几个阶段的过滤,以删除显示某些个人信息、不安全或有毒模型输出、错误自我识别数据和重复示例的示例。遵循Gemini的方法,我们发现包括鼓励更好的上下文归属、谨慎和拒绝以最小化幻觉的数据子集,可以提高事实性指标的性能,而不会降低模型在其他指标上的性能。
格式化:Gemma 2模型使用与Gemma 1模型相同的控制标记进行微调,但格式化方案不同。注意,模型明确地以标记结束生成,而之前它只是生成。有关这种格式化结构背后的动机,请参阅Gemma 1。
3. 边缘AI实现
通过这个示例,你可以在树莓派5上实现机器学习算法。
3.0 收集必要的材料
树莓派5(带兼容的电源线)
MicroSD卡(最小32 GB,推荐64 GB或更高)
带SD卡读卡器或USB适配器的计算机
HDMI电缆和显示器/电视
USB键盘和鼠标(或如果支持,则使用蓝牙)
互联网连接(通过Wi-Fi或以太网电缆)
3.1 下载并安装操作系统
访问此处了解如何在树莓派4或5上下载和安装操作系统。
https://medium.com/p/4dffd65d33ab/edit
3.2 — 安装Ollama
curl-fsSL https://ollama.com/install.sh | sh
3.3 — 运行gemma2
ollamarun gemma2:2b --verbose
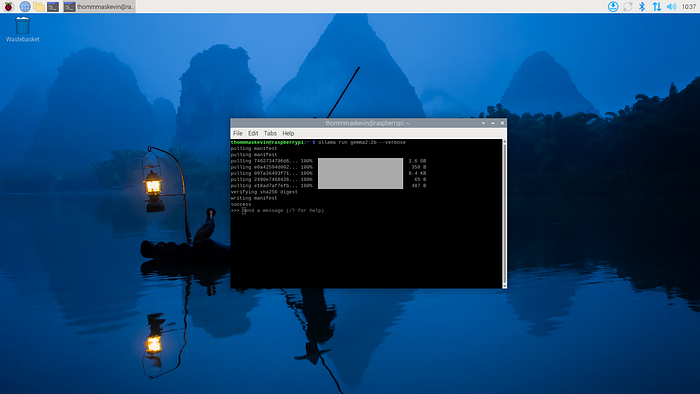
3.4 —问题结果
问题:解释Transformer ML架构

亲爱的平安好车主们,福利风暴强势来袭!平安好车主为您奉上专属宠粉盛宴 ——周六至周一,会员限时抢 50 元加油券,连续...


当前非电脑浏览器正常宽度,请使用移动设备访问本站!